一开始笔者都是使用requests+bs4实现爬虫,直到后来我发现了有一个功能强大使用简单的爬虫框架——scrapy,本文是一个入门级教程,会记录下从零开始使用scrapy实现最简单爬虫的全过程。
搭建scrapy项目
安装scrapy
第一步,安装scrapy,在命令行中输入:
1 | pip install scrapy |
当然,如果你使用的是pycharm,就可以在Project:Python → Project Interperter →
点击右侧的+号搜索scrapy进行安装。
构造scrapy框架
第二步,构建scrapy框架,在命令行中输入:
1 | scrapy startproject xxx(项目名) |
此处笔者输入了scrapy startproject hello_scrapy,便会在项目目录下生成一个hello_scrapy文件夹:
hello_scrapy文件夹内有如下结构:
第二个hello_scrapy目录内有,这里有各种各样的配置文件,作为入门教程,我们只需要了解settings.py的部分配置:spiders目录内有:
构建一个爬虫
接下来,我们在项目中构建第一个爬虫,在命令行中输入:
1 | cd 项目名 |
cd命令用于切换文件夹到项目文件夹内,scrapy genspider用于创建一个爬虫,第一个参数是爬虫名,此处爬虫名 切忌与项目名重复!
第二个参数是域名,如想要爬取的网站如果是百度百科对Python的记录:https://baike.baidu.com/item/Python/407313,它的域名便是掐头去尾剩下的部分:baidu.com
此处笔者想实现一个爬取英为财情https://cn.investing.com/网上期货数据的爬虫,便输入了以下命令:
1 | cd hello_scrapy |
输入后便会在hello_scrapy/hello_scrapy/spiders中生成一个新文件futures_spider.py(期货爬虫):futures_spider.py中的内容:
1 | # -*- coding: utf-8 -*- |
此处的pass便是我们需要输入的地方。
分析网页
观察网页源代码
我们先来浏览一下英为财情网的期货数据,我们要爬取的网页是:https://cn.investing.com/commodities/real-time-
futures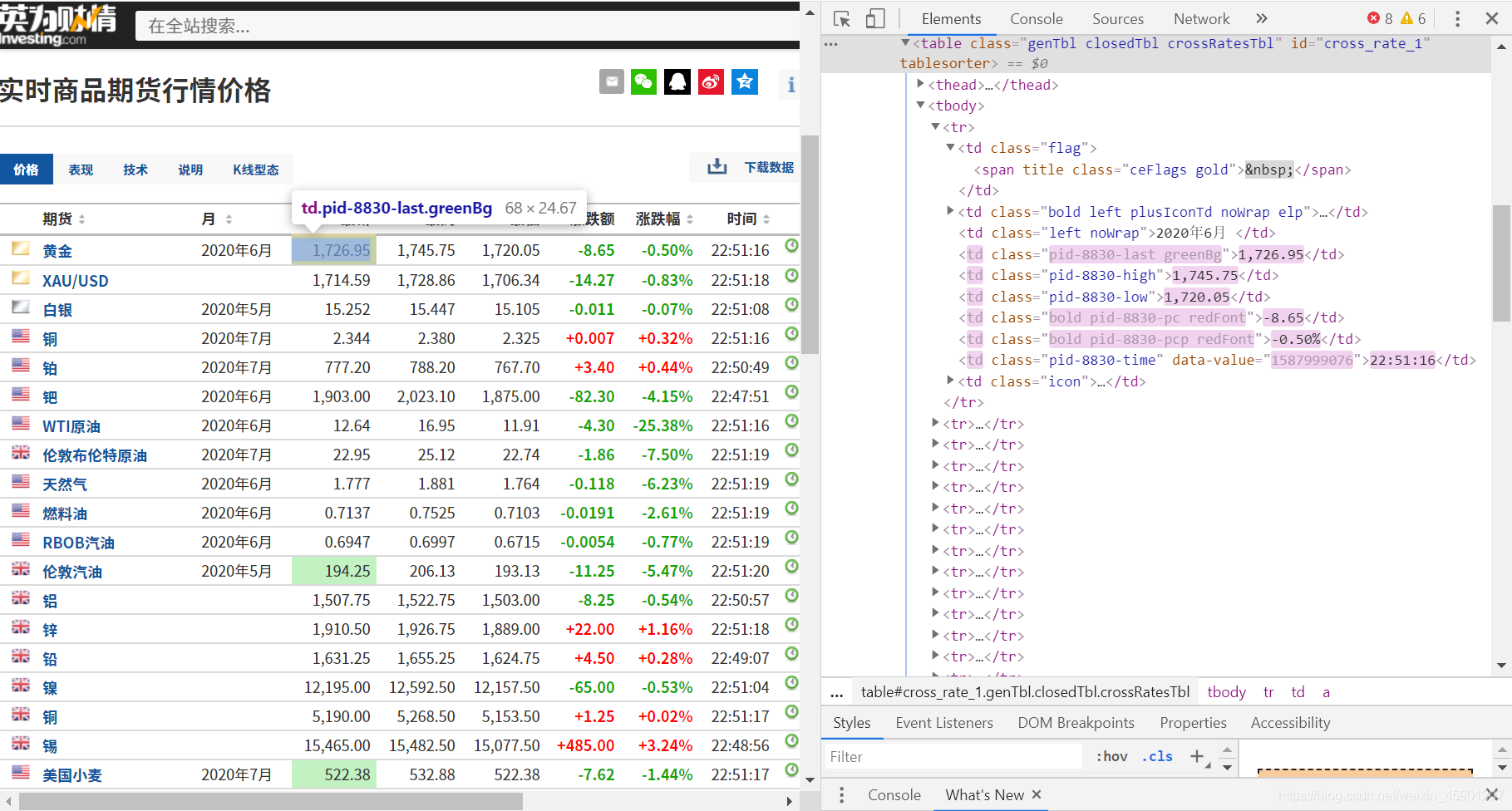
通过观察网页的结构和源代码,我们发现网页的期货数据被存储在表格结构中,接下来,我们就要对这个表格中的数据进行爬取:
学习网页结构(了解可以跳过)
作为入门教程,我们先来简单了解一下网页结构:每个网页都分为head和body,head主要用于网页的初始化,例如设置编码格式,设置标题,引入脚本,引入风格样式等;而body用于显示网页的内容,如下便是一个基础的网页结构:
1 |
|
效果如下,非常简单:
学习网页表格(了解可以跳过)
接下来,我们来了解一下网页的表格结构:
1 |
|
这是一个简单的表格:
table是表格本体table中包含tr,即table row,表示表格的一行tr中有th和td,th即table head,意为表头td即table data,意为表中数据,即表身
我们这里的表格创建了ID和Name两个表头,表中导入了四排数据,效果如下:
学习XPath语法(了解可以跳过)
在简单了解html之后,我们来了解一下xpath语法:
//表示选择所有,如//tr表示选择所有tr行./表示当前目录的下一个目录- text()表示该目录的中内容
即使不熟悉xpath,我们也有另一个办法,通过在想获取的元素上右键检查(笔者使用chrome作为浏览器),在元素上右键 → Copy →Copy Xpath,我们便可以获得该元素的Xpath: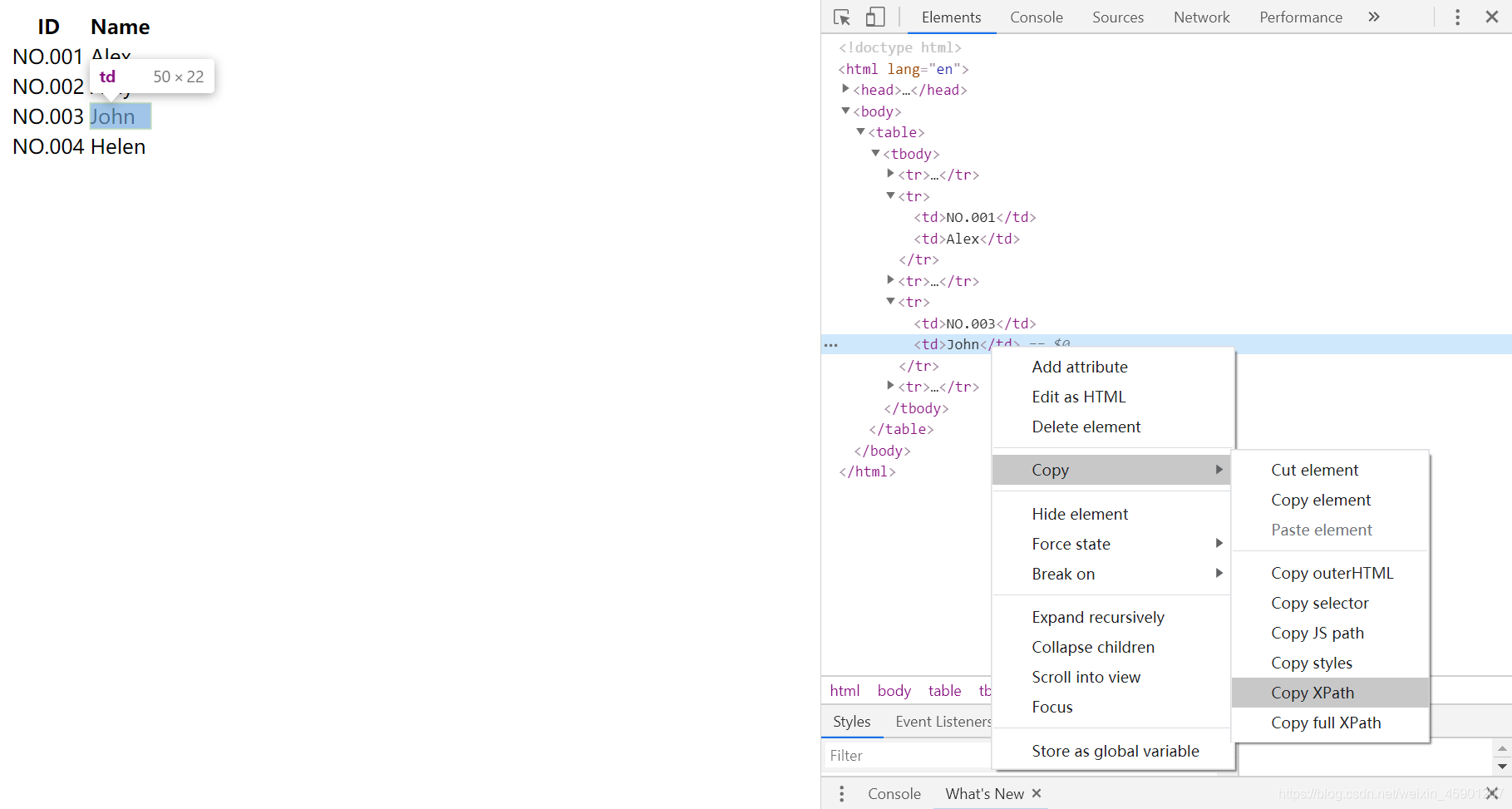
此示例获取的xpath:/html/body/table/tbody/tr[4]/td[2],当然我们也可以通过Copy full
Xpath获取完整的Xpath。
我们来观察一下此例中得到的Xpath:
John位于:
<html>- →
<body> - →
<table> - →
<tbody>(tbody与thead对应,表示表身,即使源代码中不写,浏览器编译后也会自动生成) - →
tr[4](即第4个tr,此处的tr的位置用数组形式表示索引) - →
td[2](即第2个td,同样使用索引标记位置)
在了解这些前置知识之后,我们就可以开始实现parse函数,我们再次观察要爬取的网页: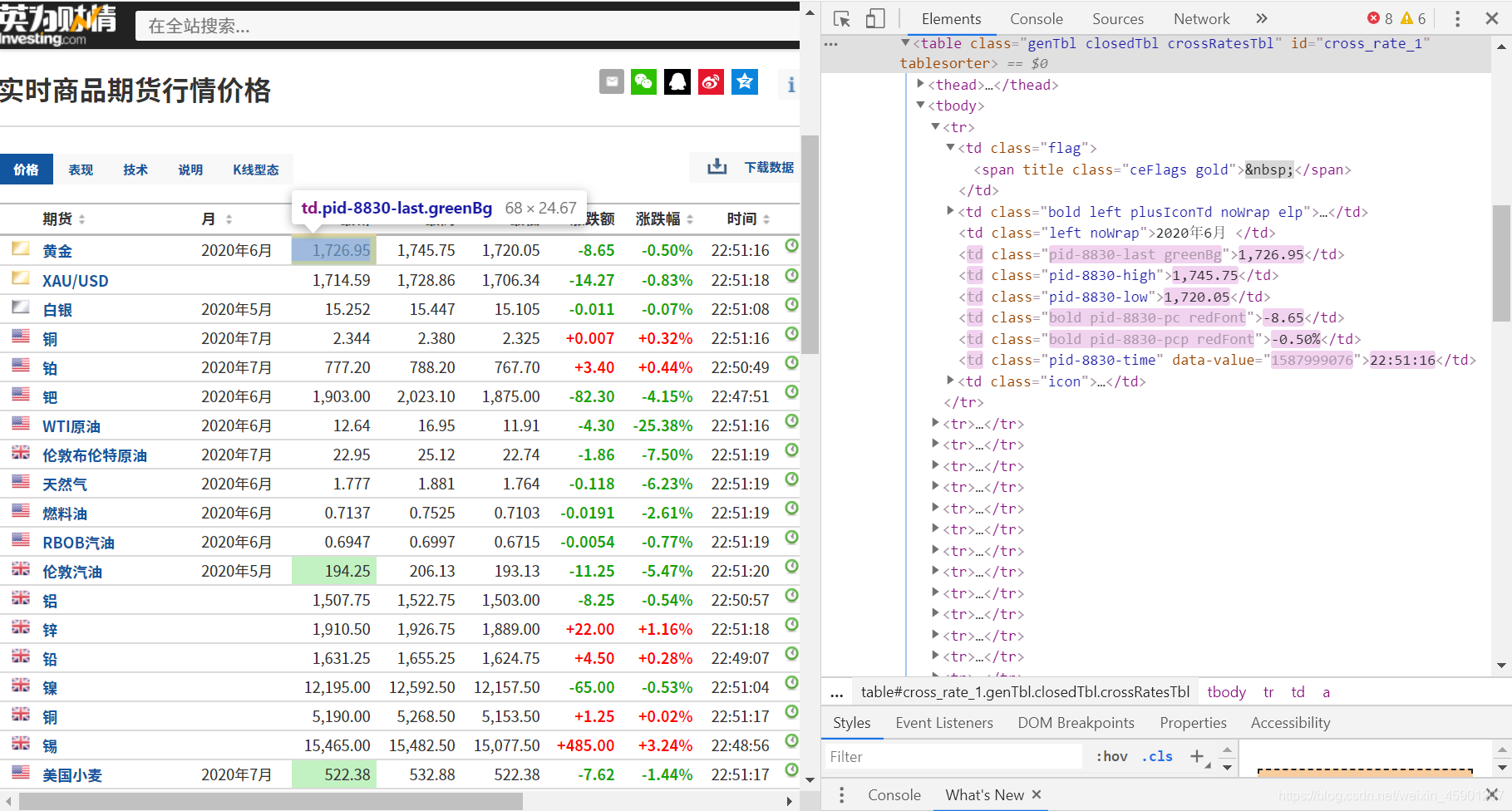
可以发现,表格中tr行的第2个数据里的超链接标签a对应商品名,第4个对应最新价,第8个对应涨跌幅。
因此,
- 商品名内容的
XPath路径为//tr/td[2]/a/text()(意为所有tr标签下的第二个td里a标签的内容) - 最新价为
//tr/td[4]/text() - 涨跌幅为
//tr/td[8]/text()
实现爬虫
修改指定的网页名
把start_urls指定的网页修改成所要爬取的网页名:
1 | start_urls = ['https://cn.investing.com/commodities/real-time-futures'] |
编写parse函数
实现parse函数(parse意为语法分析,顾名思义,用于解读网页结构获取内容)
1 | def parse(self, response): |
运行爬虫
运行命令
接下来我们来运行一下试试,运行爬虫需要在命令行中项目目录下输入如下指令:
1 | scrapy crawl xxx(爬虫名) |
笔者此处输入:
1 | scrapy crawl futures_spider |
效果如下,此处为节省篇幅只显示错误提示:
1 | 2020-04-27 23:46:28 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://cn.investing.com/commodities/real-time-futures> (referer: None) |
可以看到,网页报了403错误,意为服务器拒绝处理,这是为什么呢?
配置settings
设置ROBOT君子协议
因为我们没有在settings.py中设置一些必要的选项,settings中有一条ROBOTSTXT_OBEY,意为是否遵守君子协议,若为True,你可以爬取的格式、范围、次数等就要受到网站要求的限制,所以为了正常爬取,我们需要修改为False(你懂的):
1 | # Obey robots.txt rules |
设置请求头
然而这样设置之后还是不行,因为我们需要指定User-Agent请求头,才能把爬虫伪装成一个浏览器,User-
Agent同样可以在settings中设置:
1 | # Crawl responsibly by identifying yourself (and your website) on the user-agent |
设置之后,我们便可以得到数据啦,再次在命令行中输入:
1 | scrapy crawl futures_spider |
返回结果:
1 | 2020-04-27 23:56:01 [scrapy.utils.log] INFO: Scrapy 2.0.1 started (bot: hello_scrapy) |
这样我们就得到结果啦,接下来可以写一个writer存储数据,笔者此处便不再赘述。